In order to find and use web elements using By.cssSelector or By.xpath, it is very helpful to understand the DOM. The DOM (Document Object Model) is simply the interface that is used to interact with HTML and XML documents. When a JavaScript program manipulates elements on a page, it finds them using the DOM. If you already understand HTML, it will be very easy to understand how the DOM is organized. Rather than explaining the differences between the DOM and HMTL source code, I’ll simply direct you to this very helpful webpage:
https://css-tricks.com/dom.
If you have little knowledge of HTML, here’s an example of how web elements are organized on a page:
<html>
<head>
<title>My Web Page</title>
</head>
<h1>My Web Page</h1>
<p>This is a paragraph</p>
<a href=”http://www.google.com” >Here’s a link to Google</a>
<table border=”2″>
<tr>
<td>Row 1, Column 1</td>
<td>Row 1, Column 2</td>
</tr>
<tr>
<td>Row 2, Column 1</td>
<td>Row 2, Column 2</td>
</tr>
</table>
</html>
If you’d like to see what this webpage would look like, you can simply copy and paste this html code into a notepad file and save it with the .html extension. Then find the file in the folder where you’ve saved it and double-click on it. It should open up as a webpage.
Now let’s take a look at the various elements on the page. Note that each element has a beginning and ending tag. For example, the line that says “This is a paragraph” has a <p> tag to indicate the beginning of the paragraph and a </p> tag to indicate the end of the paragraph. Similarly, the title of the page has a beginning tag: <title> and an ending tag: </title>.
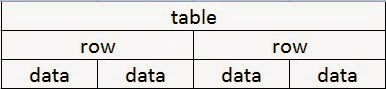
Notice that elements can be nested within each other. Look at the <table> tag, and then find the </table> tag several lines below it. In between the tags, you will see row tags (<tr>) and table data tags (<td>). Everything in between the <table> and </table> tags is part of the table. Now look at the first <tr> tag and the first </tr> tag. Notice that there are two pairs of <td></td> tags in between. Everything between the first <tr> tag and the first </tr> tag is a row of the table. The <td></td> pairs in the row are elements of data in the row.
Now imagine that this data is organized into tree form:
If you were going to traverse the DOM in order to get at the data in Row 1, Column 1, you’d start by finding the <table> element, then by finding the first <row> element, then you’d find the first <data> element. This is how we will use css selectors and the xpath to find elements in the next blog post.
If you’d like to find out more about HTML and CSS, I highly recommend the w3schools website.