Did you know that there is a wealth of testing tools right in your browser? Web browsers like Chrome and Firefox have developer tools that are available for free, for everyone. And these tools are not just for developers! In this post, I’ll be sharing six ways that Chrome DevTools can help you with your testing.

To access Chrome DevTools, simply click on the three-dot menu in the upper right corner of your browser, choose “More Tools”, and then choose “Developer Tools”. DevTools will open up alongside your browser window. You can customize where you would like the tools to display by clicking on the three-dot menu in the DevTools nav bar and selecting an option for “Dock Side”. You can choose to have the DevTools display on the left, on the right, on the bottom, or in a separate window.
Here are some of the things that Dev Tools can do:
1. Inspect an HTML Element
Have you ever been writing UI automation and you just can’t figure out how to access an element? With DevTools, you can right-click on the element and choose “Inspect”, and the Elements pane of DevTools will show you the element in the HTML. You can then use this information to figure out the best way to access the element.
2. Edit HTML Elements
Not only can you find an element in the HTML, you can also edit it! This is great for security testing. Imagine that there is a page with a button that is hidden for users who are not admins. A malicious user could find that element using DevTools, remove the “hide” tag, and use the button. So it’s helpful to try this while testing to verify that there’s an additional check for user permissions when the button is used.
To edit an element, right-click on it in the HTML displayed in the Elements pane, and choose “Edit as HTML”. Make whatever edits to the element you want, then click out of the edit box. You should see the element on the page change as a result of your edits.
3. View HTTP requests
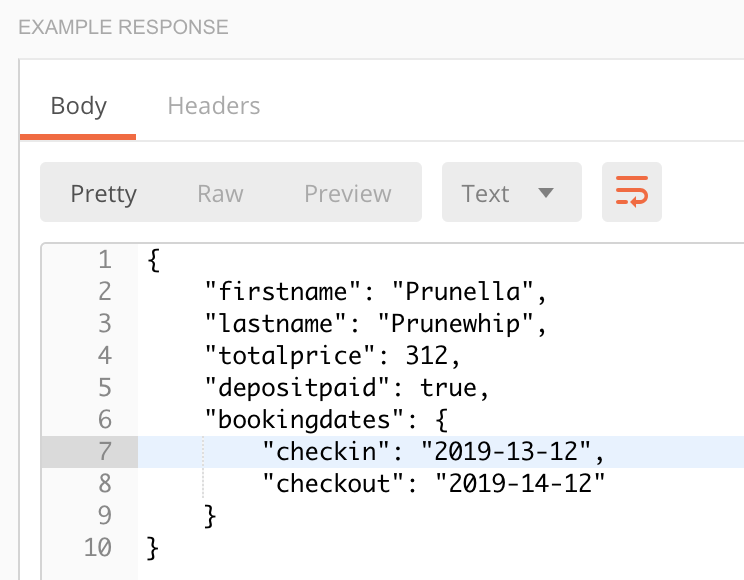
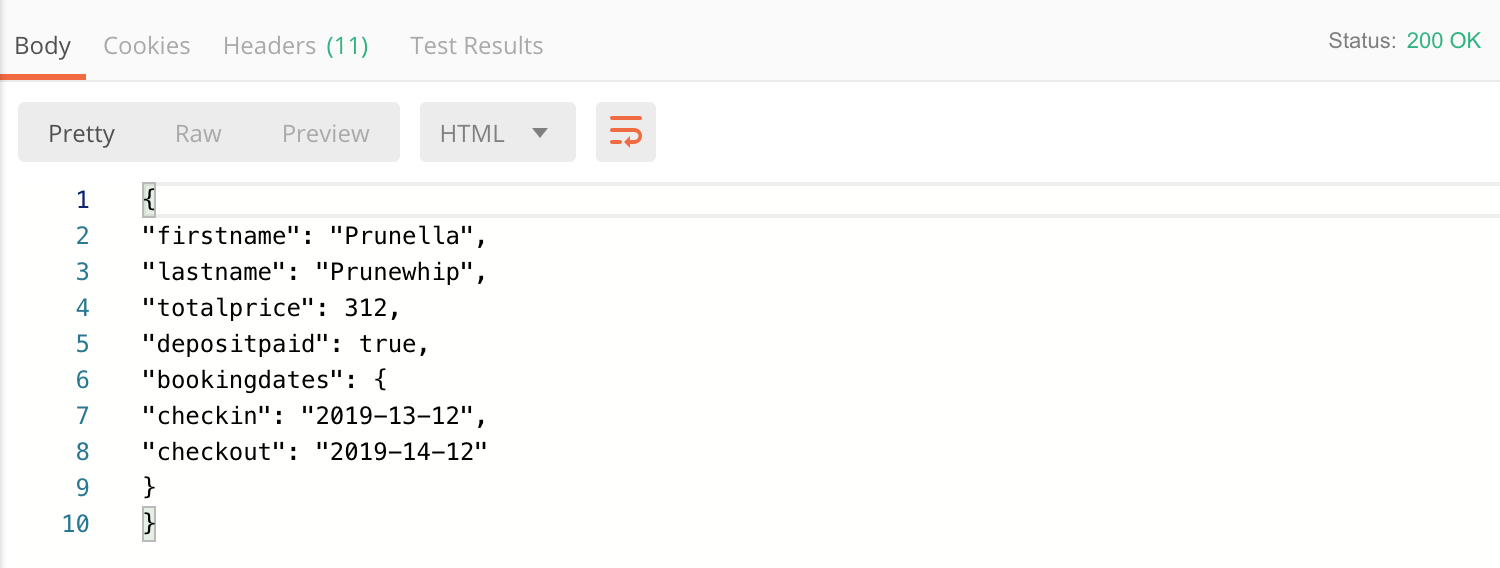
If you click on the Network tab of DevTools, you can see all of the requests made to the server while using a web page. This includes API calls, which you can then copy and use in a tool like Postman. This feature is helpful for determining if your page is making the API calls that you are expecting, and it’s also great for security testing. For example, just because the front-end of a web page doesn’t allow a user to submit a field with more than 50 characters doesn’t mean that it can’t be done. If a malicious user copies the API call and submits it through Postman, through a curl command, or through some other tool, they may be able to send more than 50 characters directly to the server. This is why it’s important to have both front-end and back-end validation on a website.
4. Simulate device frames
When you are testing a webpage, it’s important to make sure that the page appears correctly on both laptops and mobile devices. But even the most well-equipped tester doesn’t have access to every single device in use today. So DevTools comes with a simulator that shows roughly what your webpage will look like on various devices. To access this feature, click on the device logo
in the toolbar. This will open the simulator in the webpage side of the browser. Then you can use the dropdown to select specific devices (which seem to be a bit obsolete), or you can choose the “Responsive” setting and then manually expand or contract the window to get the size you want. The exact size is displayed in the navbar at the top.
5. Simulate performance on slower networks
Testing a webpage while in your office usually means you are using a great high-speed network. But what about your users who have slower connections? You can use DevTools to simulate slower connections and throttled CPU, which could help uncover race conditions in your application. To use this feature, go to the Performance tab in the navbar. In the Network dropdown, you can choose “Fast 3G”, “Slow 3G”, or “Offline”, and in the CPU dropdown, you can choose “No throttling”, “4x slowdown” or “6x slowdown”. Don’t forget to reverse your changes when you are done testing!
6. Investigate page load errors
As I was creating this post, I was reminded of one more way that DevTools are helpful. I was trying to upload the Chrome logo to my post, and the popup that I usually use to add an image was completely blank. I went to the Console tab of DevTools and saw that there was a 404 “File not found” error when I clicked on the Add Images button in Blogger. When you are testing your team’s application and you’ve found a bug on a page, checking for errors in the console can help you give more information to your developers so they can get to the root of the problem more quickly.
Sometimes the most useful testing tools are right there in front of you! I hope this post has inspired you to take a look at DevTools to see how it can help you in your testing.